
Predicting Top 4 Teams in Soccer League by Classification
Summary
This blog is based on my 3rd data science project at Metis/Chicago, which is about using classification algorithms to solve practical problems.
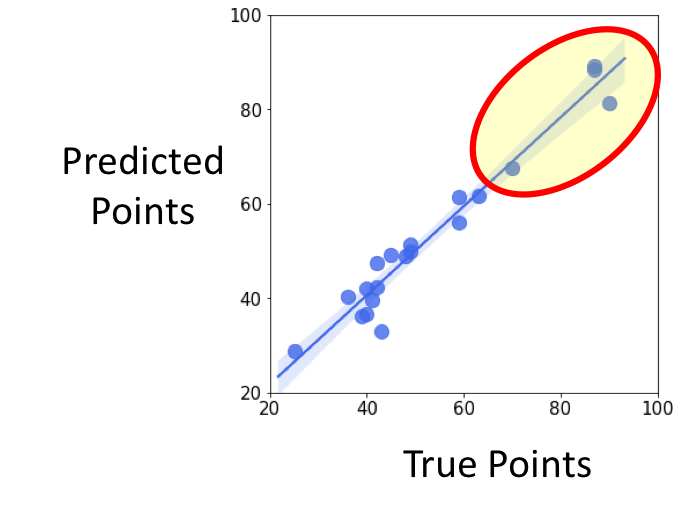
In the last project, I built a linear regression model to predict the final points for teams in the Spanish Soccer league (also called La Liga). Two primary features include goals scored and goals lost. For each team in the league, the predicted points agree quite well with the true data, with result summarized in Figure 1.
For this work, I will be using the same dataset from last project but focusing on using classification models to predict the top 4 teams in the league, which will be qualified for the next year’s Champions League ( reputation and money for the team and players.)
Analysis Approach
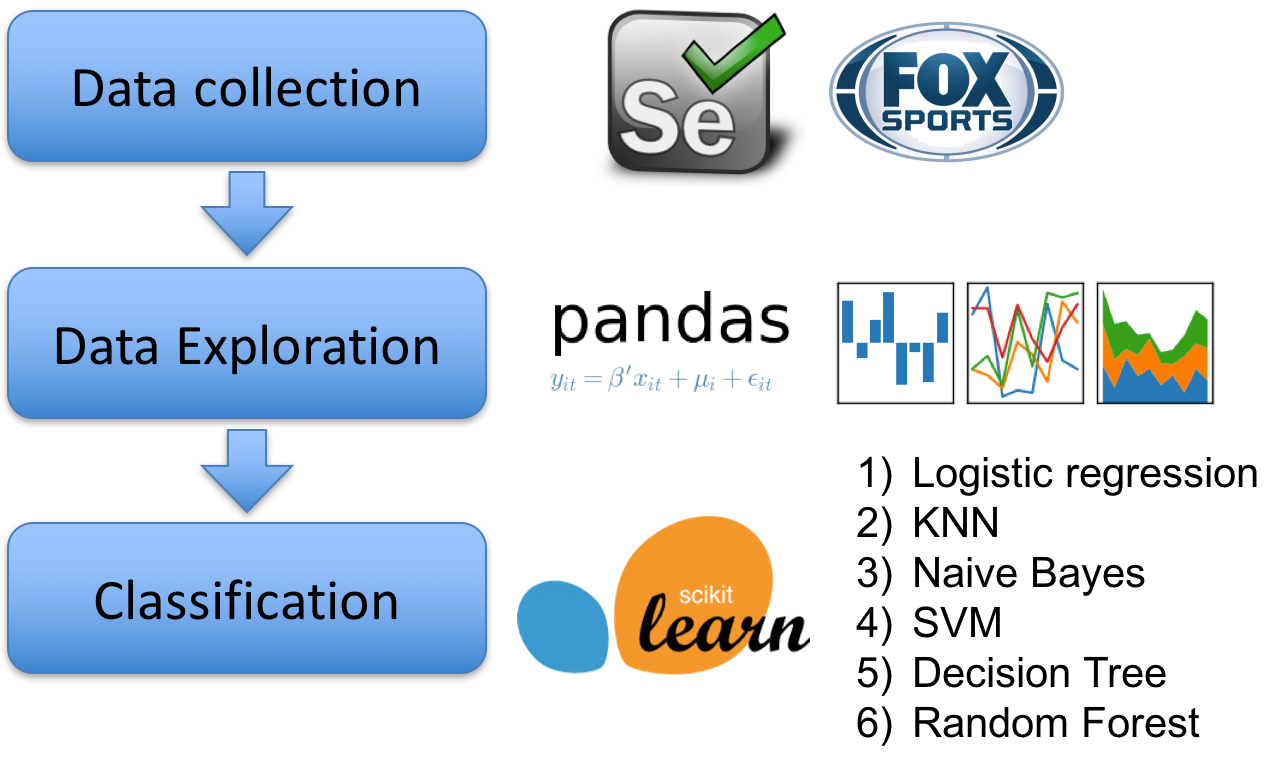
Soccer data for past 20 years was scraped from Fox sports and Wikipedia by selenium. The data was uploaded and stored in SQL. Pandas was applied for data cleaning, standardization, and exploration. Finally, I used the scikit learn, the machine learning package in python, and 6 different built-in classifiers for this study and optimized based on the overall results.
Tools used in this project were summarized in Table 1, and the features and target were illustrated in Figure 2 and
Table 1. Tools used in this project.
| Application | Tools used |
|---|---|
| Data scraping | BeautifulSoup and Selenium |
| Data Exploration | SQL, Pandas |
| Plotting and visualization | Matplotlib |
| Classification package | Scikit-learn |
| Classification models | Logistic regression, KNN, Naive Bayes, SVM, Decision Tree, Random Forest |
Results & Discussion
Data Exploration
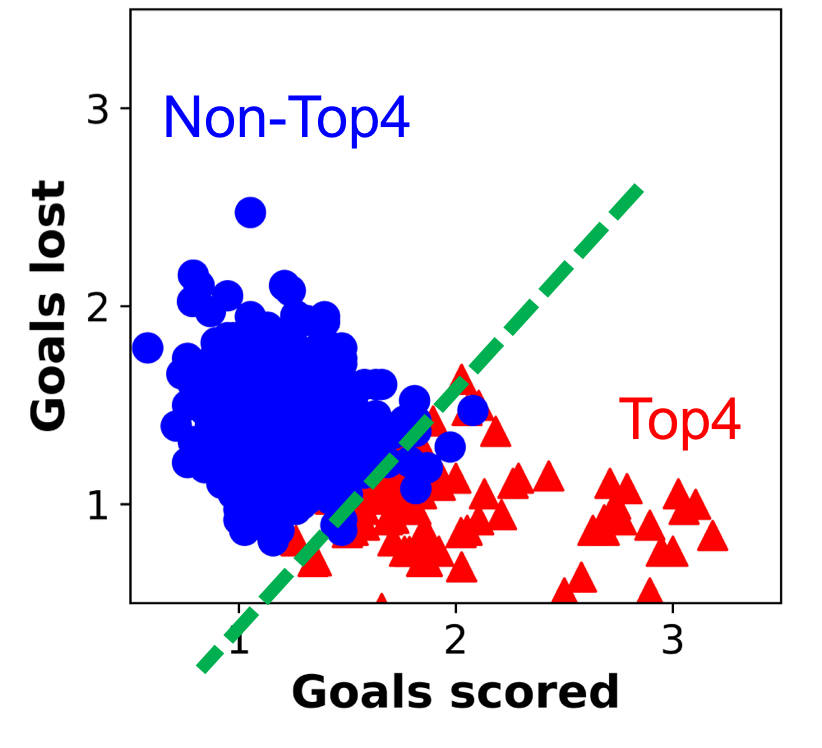
I started exploring the data by plotting with features and labels, as shown in Figure 3. Two primary features were included: goals scored per game and goals lost per game. The dataset was separated to two classes: top 4 or not-top-4. The objective of this project is to find the optimal cutting-off rule to separate out these two class. This graph seems reasonable in the sense that, usually, top teams would scored more goals and lose less goals.
Model prediction
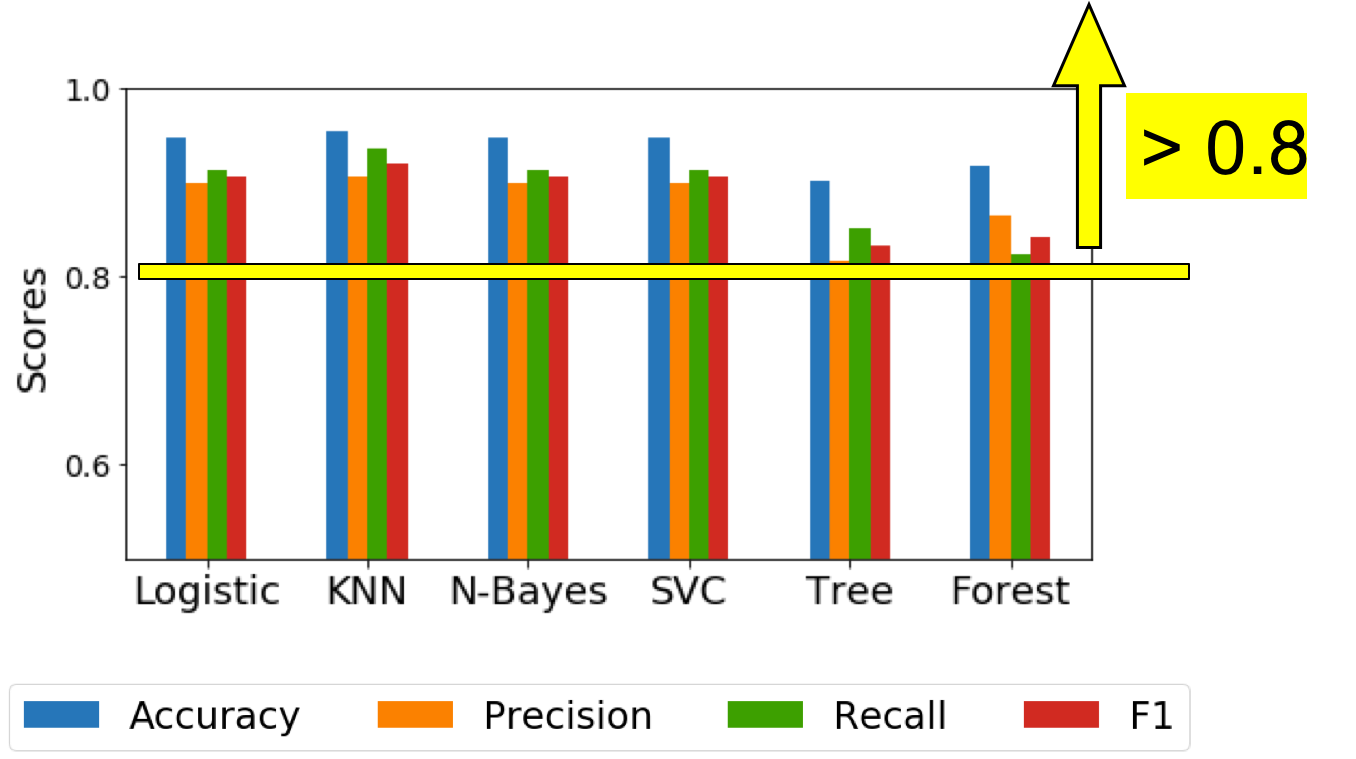
Figure 4 shows optimized results and final scores (accuracy, precision, recall and F1) for 6 classification models. Usually, higher scores indicate better predictions. As we can see, all scores are more than 0.8, implying similar and reasonable predictions from all classifiers.
Contribution of individual players matters
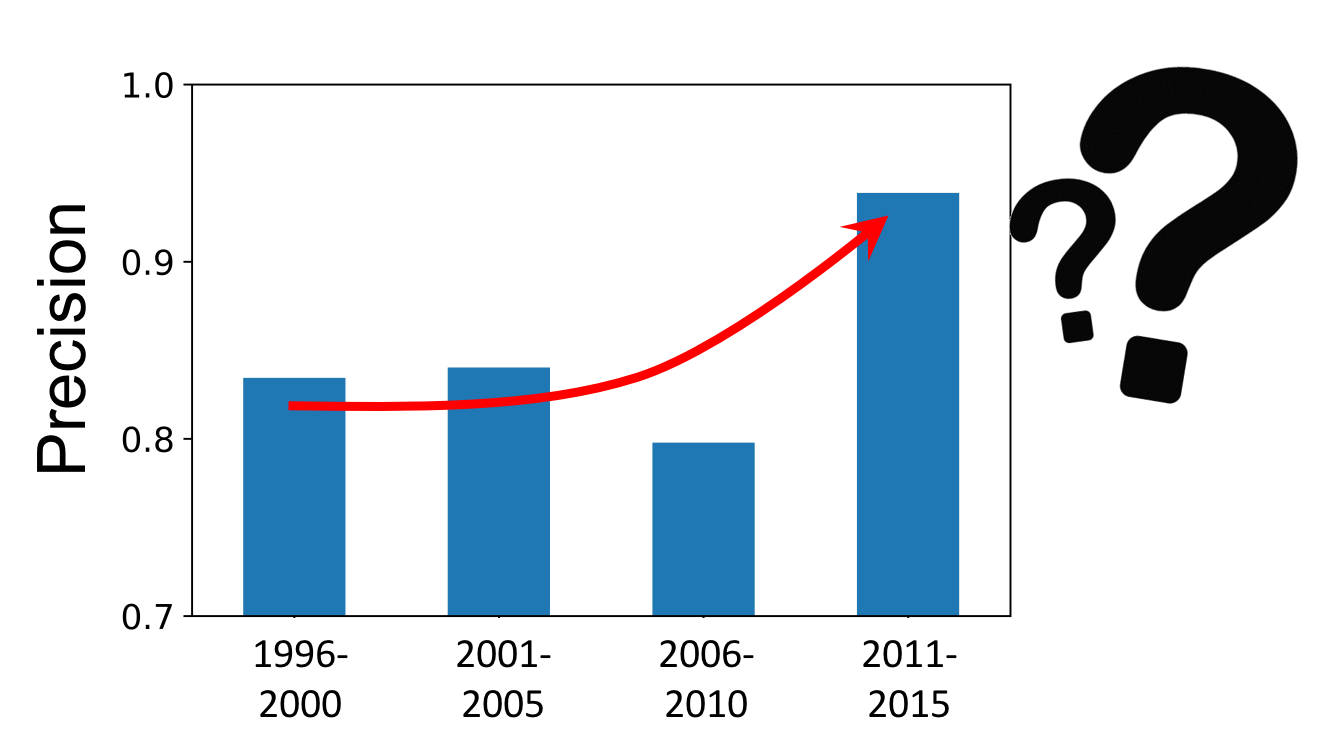
Apart from the modeling, what I found most interesting about data science is to explore and discover something new. In this project, when I took a look at the prediction over time, something interesting came up. According to Figure 5, we can clearly see that, the average precision scores based on 6 models, is increasing over time, indicating that the model is becoming better after the year of 2010.
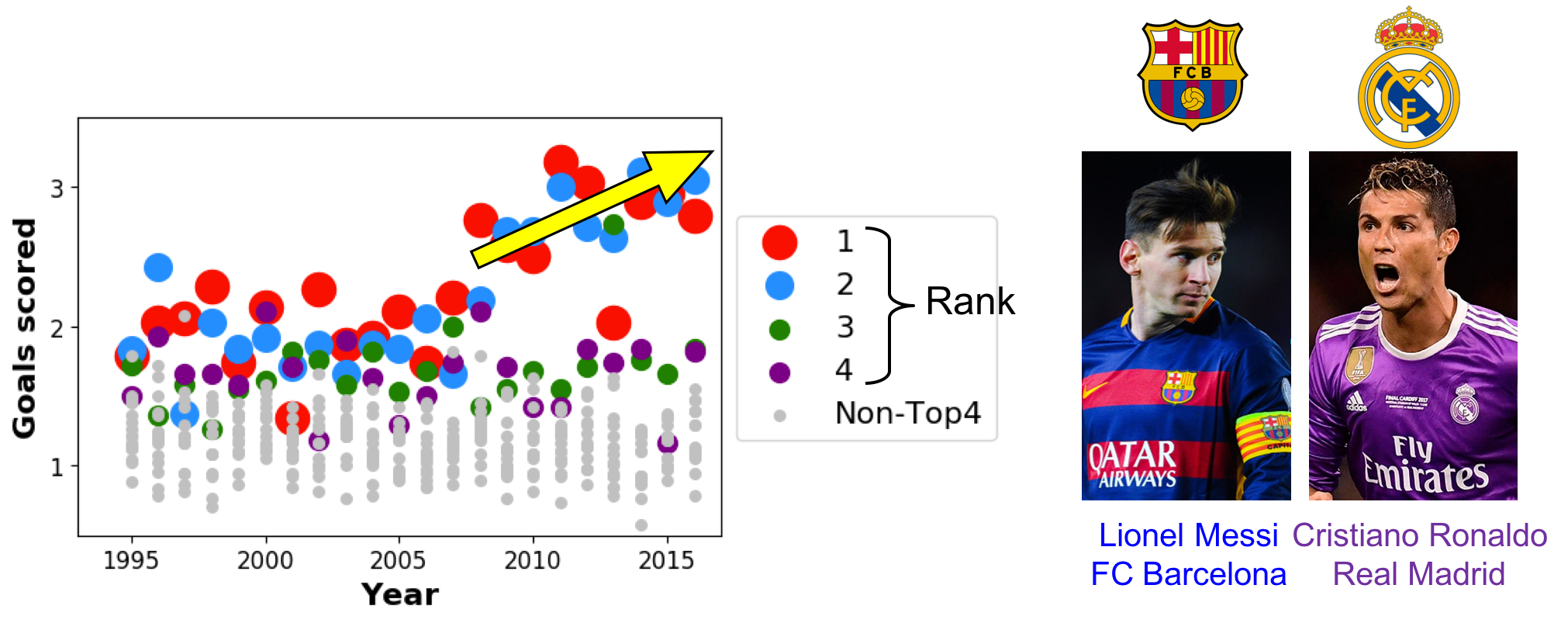
If we look at the primary feature, of ‘goals scored per game’ over time, the goals scored for top teams are increasing after 2010, particularly for top 2 teams. The most possible reason is these two players from two clubs, Lionel Messi from the club of Barcelona, Cristiano Ronaldo from the team of Real Madrid. They are possibly 2 best soccer players, from 2 best soccer teams in the world, spanning past 10 years.
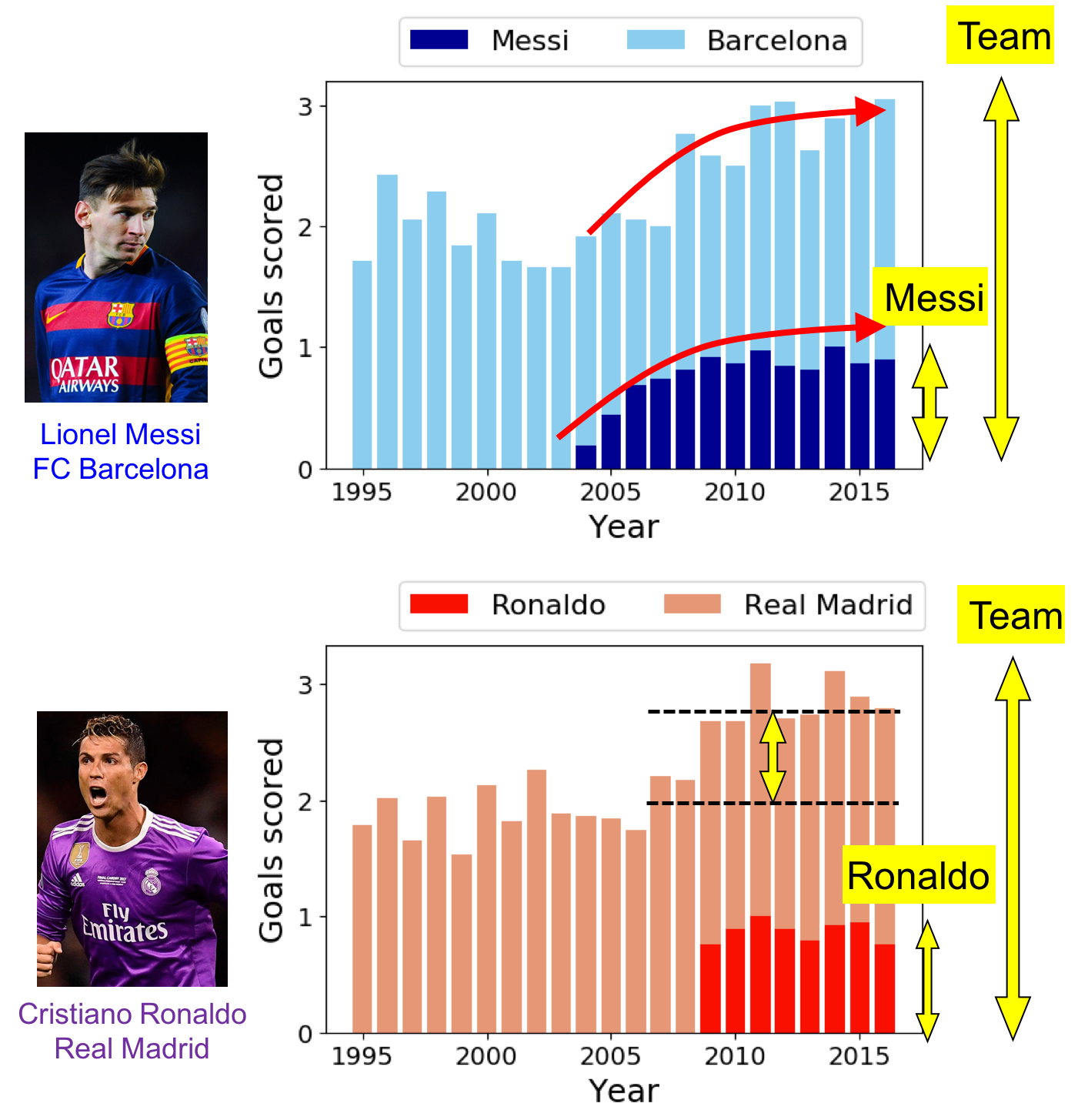
Here, we are looking at the contribution of a player to the team over time. As we can see in Figure 7, Messi became as a regular player in 2004, and scores so many goals from 2008. Besides, the increasing trend of Barcelona’s goals fits well with Messi’s goals, which probably indicates that contribution of Messi is critical for the improvement of the team. The same trend applies to Ronaldo and Real Madrid.
With that in mind, let us get back to the classification model, these two extraordinary players made their teams outperform the rest teams, easily secure two positions in top 4. In other words, it is relatively easy for classification models to isolate these 2 teams, simply because they are so good.
Conclusions
- It is feasible to use machine learning algorithm to predict whether a team is top 4 based on the goals scored and goals lost.
- Although soccer is a team sports (with 11 players in each team), an outstanding individual would have a significant effect on the team, even the league.