
Predicting Points in Soccer League by Regression
Introduction
This blog is built on my second data science project at Metis/Chicago, which consists of two parts:
- Scrape the information from the web
- Apply linear regression model to correlate features (goals) with target (total points)
Analysis Approach
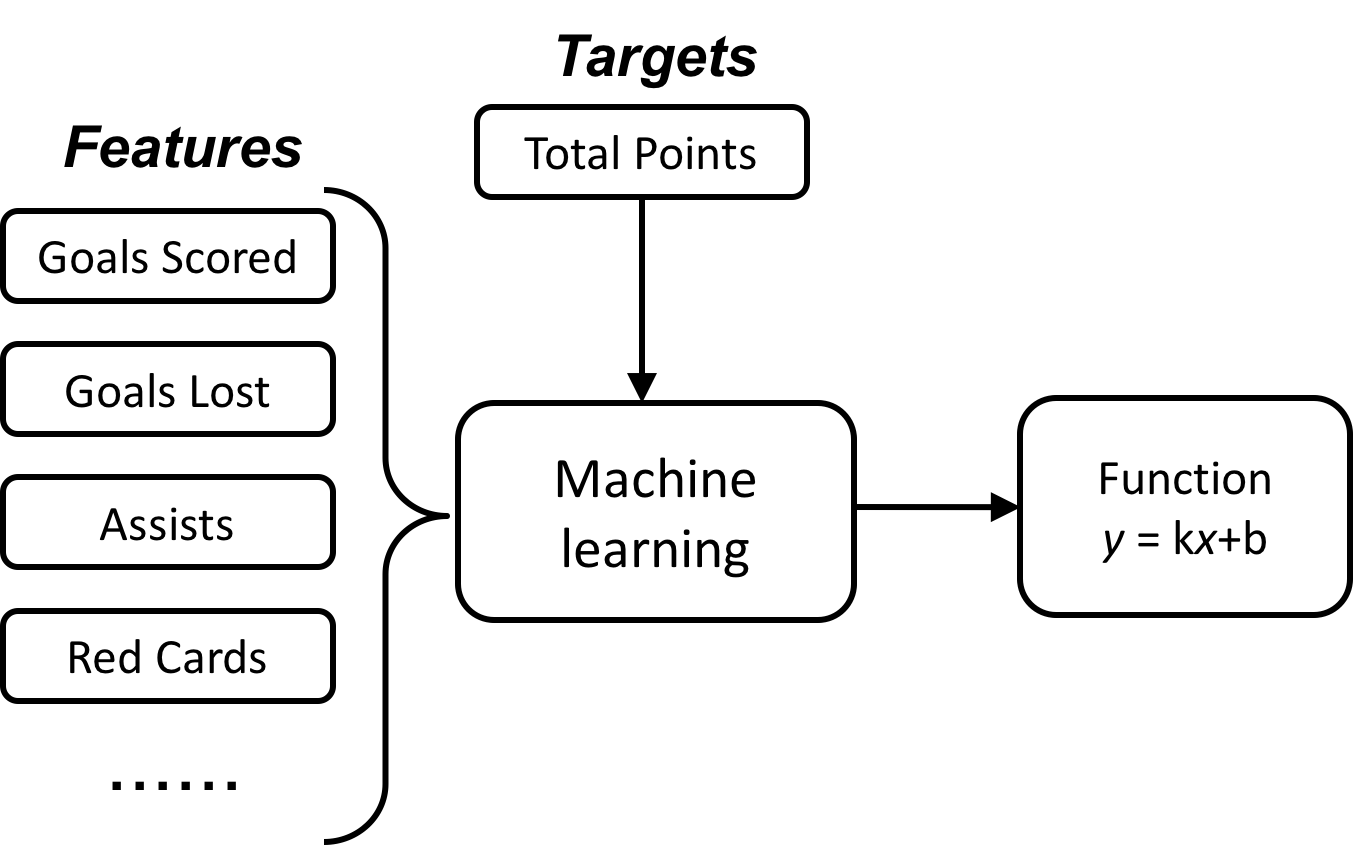
The datasets are standings and statistics of games in the Spanish Soccer League (also called La Liga). The data was scraped from Fox sports by BeautifulSoup and Selenium. The statistical data spanned across 4 seasons (from 2013 to 2017), and it was split into two sections: 2014-2017 data (for training linear regression model), and 2013-2014 data (for cross-validation). The features and target were illustrated in Figure 1 and the tools used in this project were summarized in Table 1.
Table 1. Tools used in this project.
| Application | Tool used |
|---|---|
| Data scraping | BeautifulSoup and Selenium |
| Data Exploration | Pandas |
| Linear Regression | Scikit-learn, Statsmodels |
| Plotting and visualization | Matplotlib, Seaborn |
Results & Discussion
Data Exploration
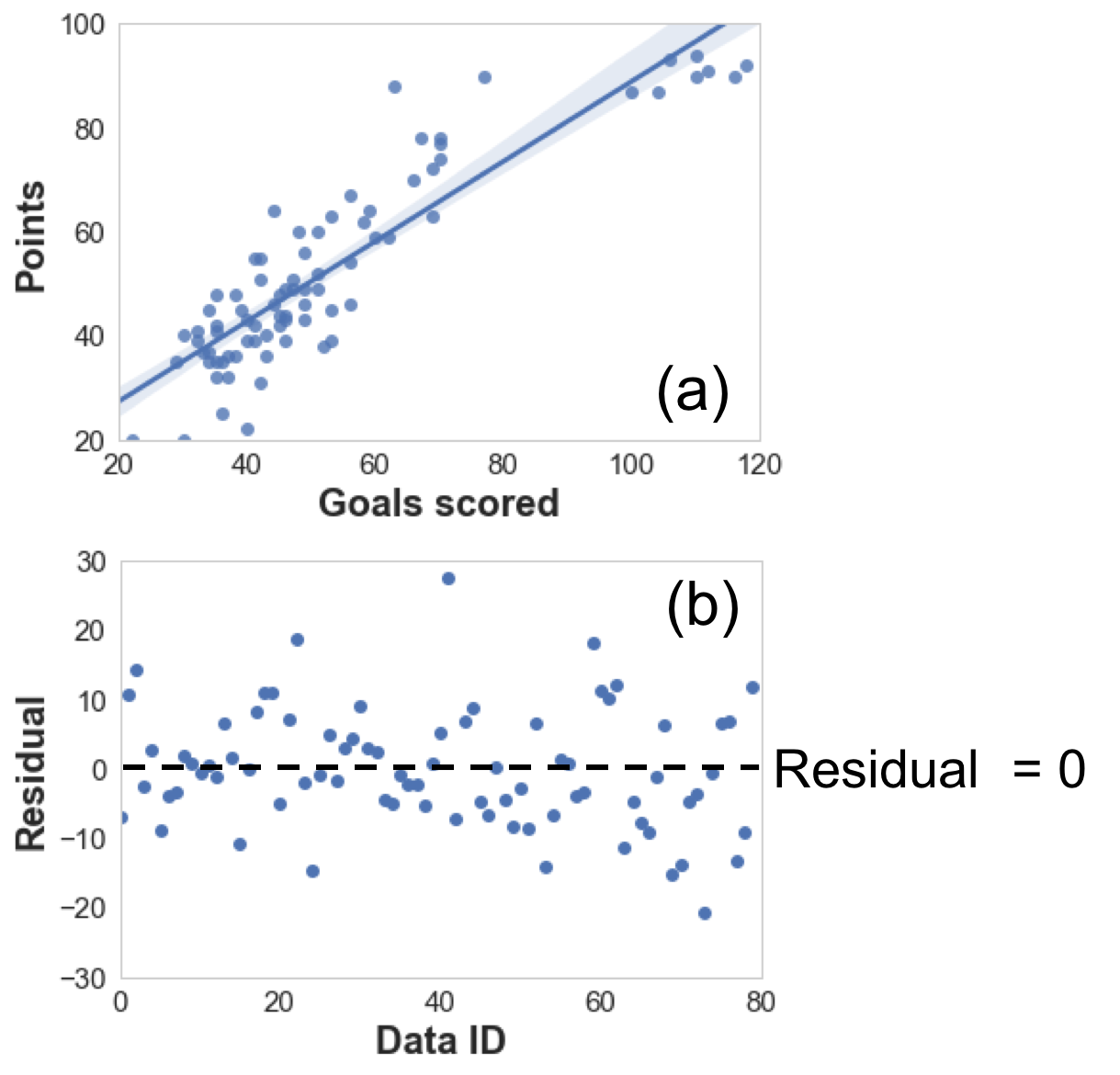
I started exploring the data by considering one single feature of “Goals scored” and plotted the “final points” against “Goals scored” in the scatter plot, as shown in Figure 2(a). The residuals in Figure 2(b) seems randomly distributed, implying that the linear regression could be a reasonable starting point.
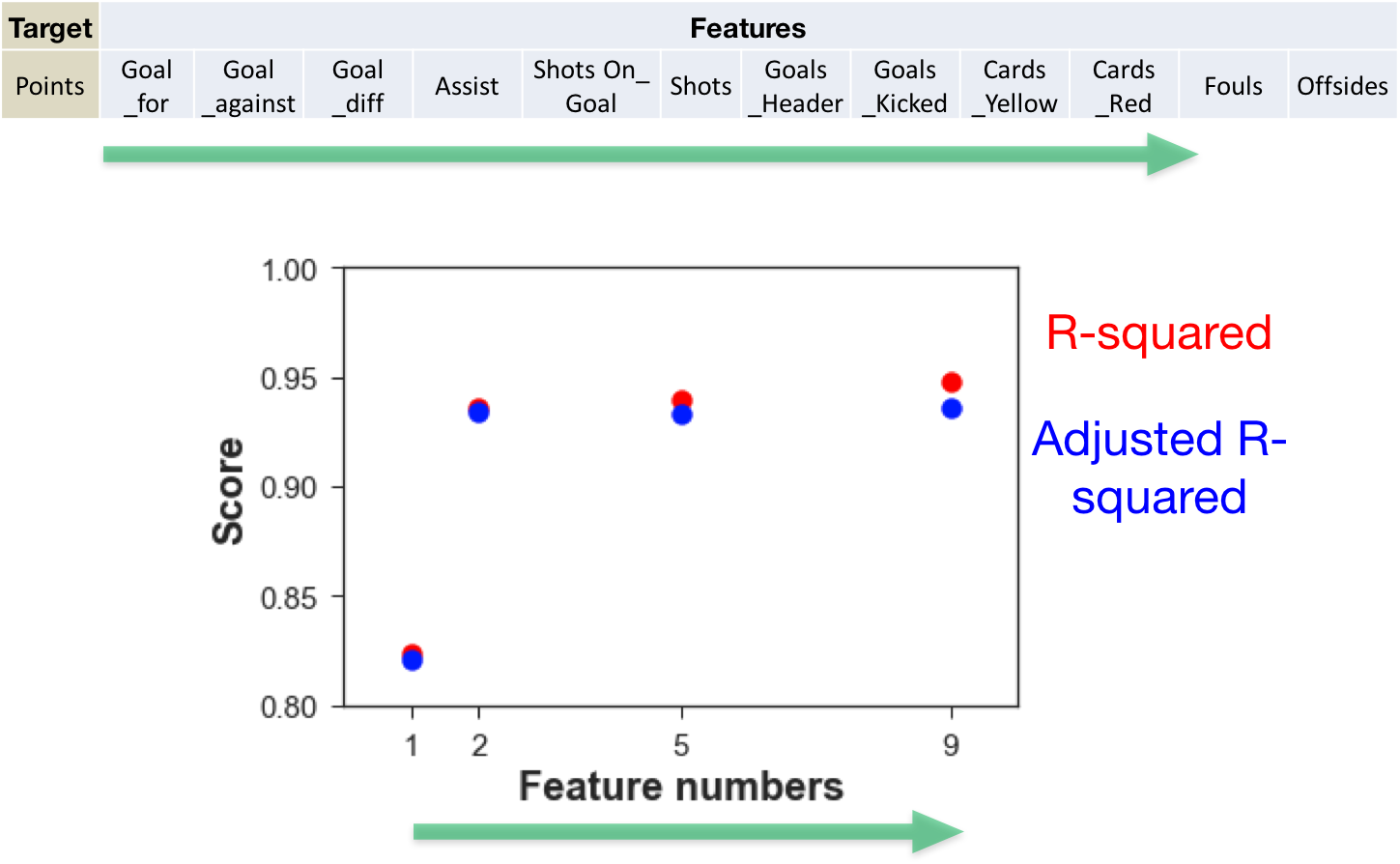
Next, I added more features to further improve the model. Although we cannot totally rely on the R scores to justify the correlation, they give a first estimation on the linear correlation. As shown in Figure 3, including more features slightly increases the accuracy of the model.
Optimization
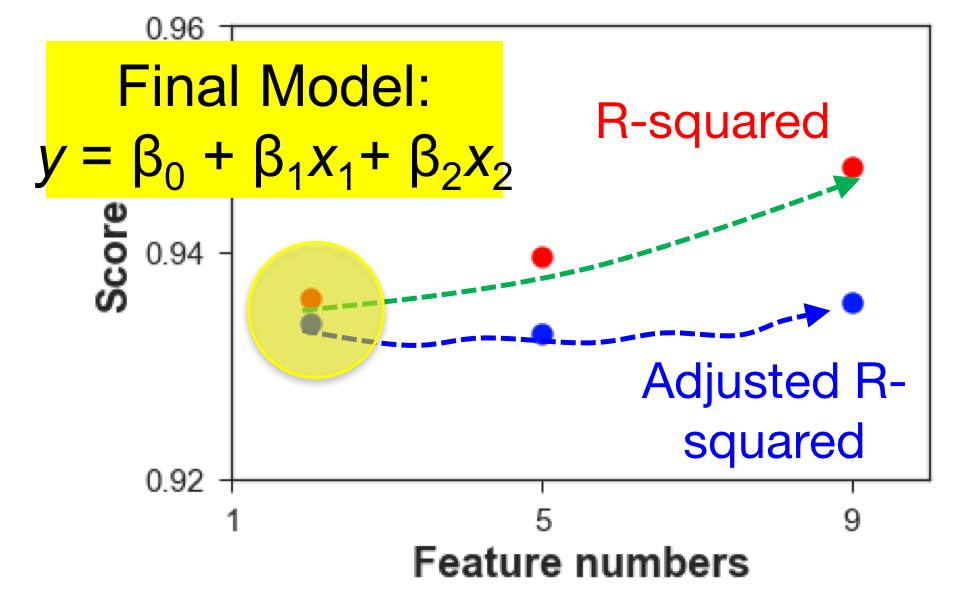
Care should be taken when dealing with the R scores: adding more features undoubtedly improves the R square, but it does not guarantee the significance of the linear correlation. The adjusted R-square, which considers the effect of the feature numbers, approximately remains constant, indicating that the rest features (after first two variables) does not have a significant effect on the model. The final model I used is the one considering two primary features: “goals scored” and “goals lost”. The high R score implies the low bias, and limited 2 features and 1 degree indicate the low complexity, ensuring that the model does not suffer from overfitting.
Validation
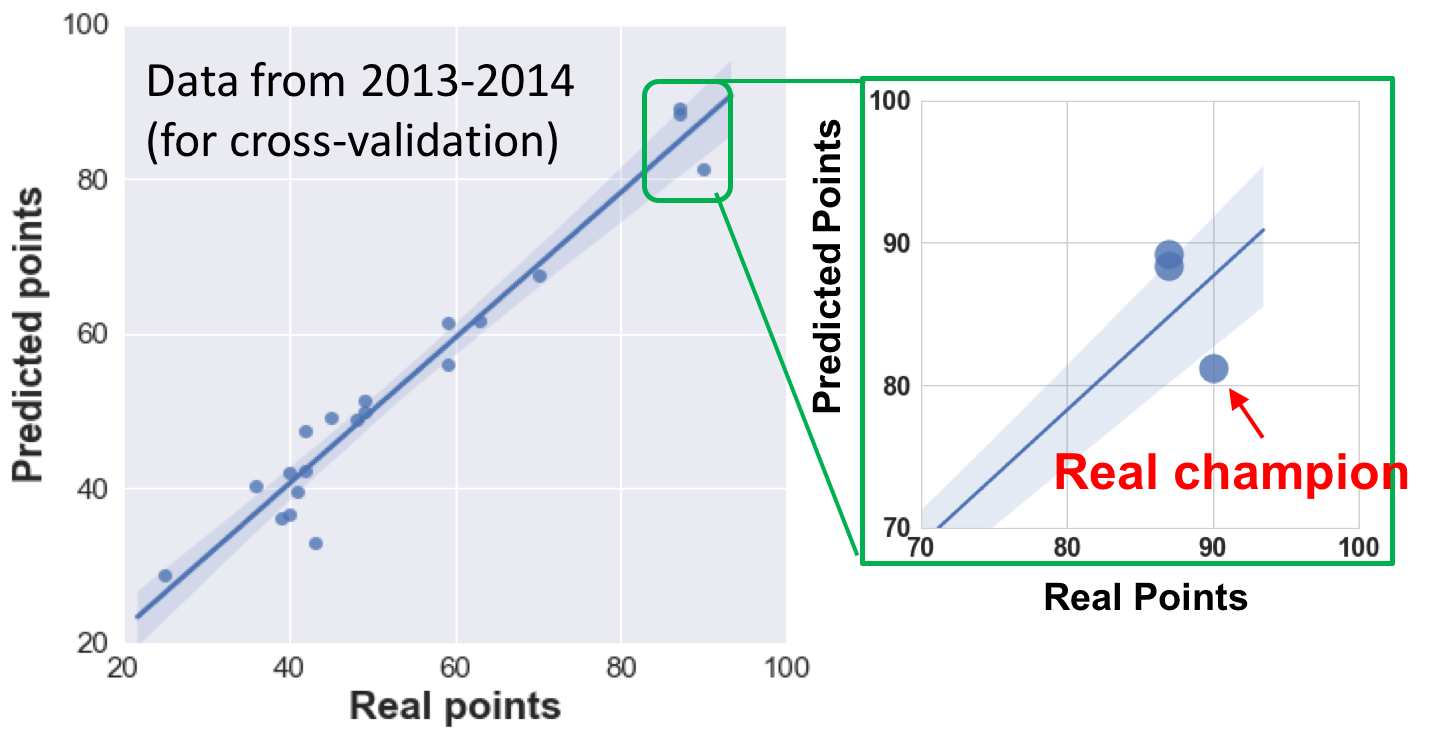
Finally, I validated the model with the test data, from 2013 to 2014 season, which is not included in building the model. Figure 5 compares the true points against the predicted points. The linear agreement appears reasonable, which means that the linear model offers a good first-order prediction. However, the model does not correctly predict the champion of the season (lower predicted points, but higher true points). More feature engineering is needed in the future work.
Conclusions
- It is possible to correlate the points with features in soccer games by linear regression.
- Linear regression gives a reasonable approximation on the final points, but more in-depth analysis is necessary
References
- Front image: www.vbetnews.com